Using ettbc: Emulating a Target Trial for Breast Cancer Screening
2026-05-04
2 Example Data
The package ships with three synthetic datasets that mimic the structure of the original study data (but contain entirely simulated values).
Months are numbered consecutively from 1 (January 2000) to 108 (December 2008). Participants enter the study between months 1 and 60.
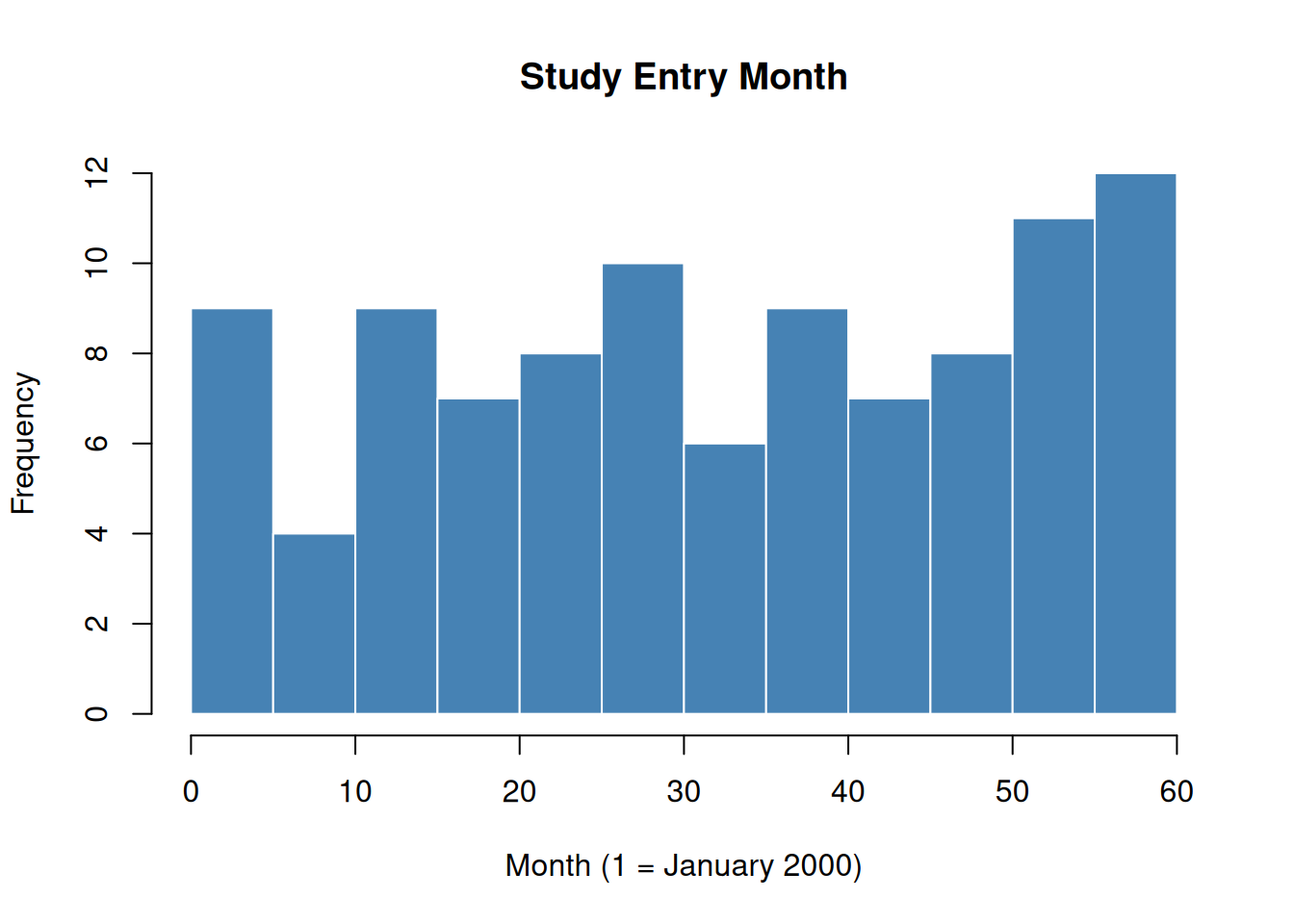
Figure 1: Distribution of study entry months in the simulated cohort.
3 Step 1: Clone and Censor
clone_censor() takes the cohort and mammography event datasets and returns a data frame with two rows per participant — one for each arm.
Code
cloned <- clone_censor(
cohort,
screening_mammograms,
diagnostic_mammograms
)
nrow(cloned) # should be 2 × nrow(cohort)
#> [1] 200
head(cloned[, c("id", "arm", "start_month", "end_month",
"censor_month", "fup", "died", "bc_died")])
#> id arm start_month end_month censor_month fup died bc_died
#> 1 1 STOPBASE 26 38 38 13 0 0
#> 2 2 STOPBASE 33 45 45 13 0 0
#> 3 3 STOPBASE 28 42 42 15 0 0
#> 4 4 STOPBASE 1 12 12 12 0 0
#> 5 5 STOPBASE 17 28 28 12 0 0
#> 6 6 STOPBASE 40 52 52 13 0 0The key new columns are:
arm: trial arm ("STOPBASE"or"CONTINUE")end_month: final observed month (minimum of death, administrative censoring, and protocol censoring)censor_month: month of protocol deviation censoring (NAif not censored for protocol non-adherence)fup: follow-up time in monthsdied: overall mortality indicator (1 if death caused end of follow-up)bc_died: breast cancer mortality indicator
Censoring Patterns by Arm
Because participants in STOPBASE are censored when they get a screening mammogram, annual screeners are censored early in that arm. Conversely, participants in CONTINUE are censored when they go too long without a mammogram, so non-adherers are censored early.
Code
par(mfrow = c(1, 2))
stopbase <- cloned[cloned$arm == "STOPBASE", ]
continue <- cloned[cloned$arm == "CONTINUE", ]
hist(stopbase$fup,
breaks = 20, main = "STOPBASE",
xlab = "Follow-up (months)", col = "#E05C4B", border = "white",
xlim = c(0, 110)
)
hist(continue$fup,
breaks = 20, main = "CONTINUE",
xlab = "Follow-up (months)", col = "#4B8FE0", border = "white",
xlim = c(0, 110)
)
par(mfrow = c(1, 1))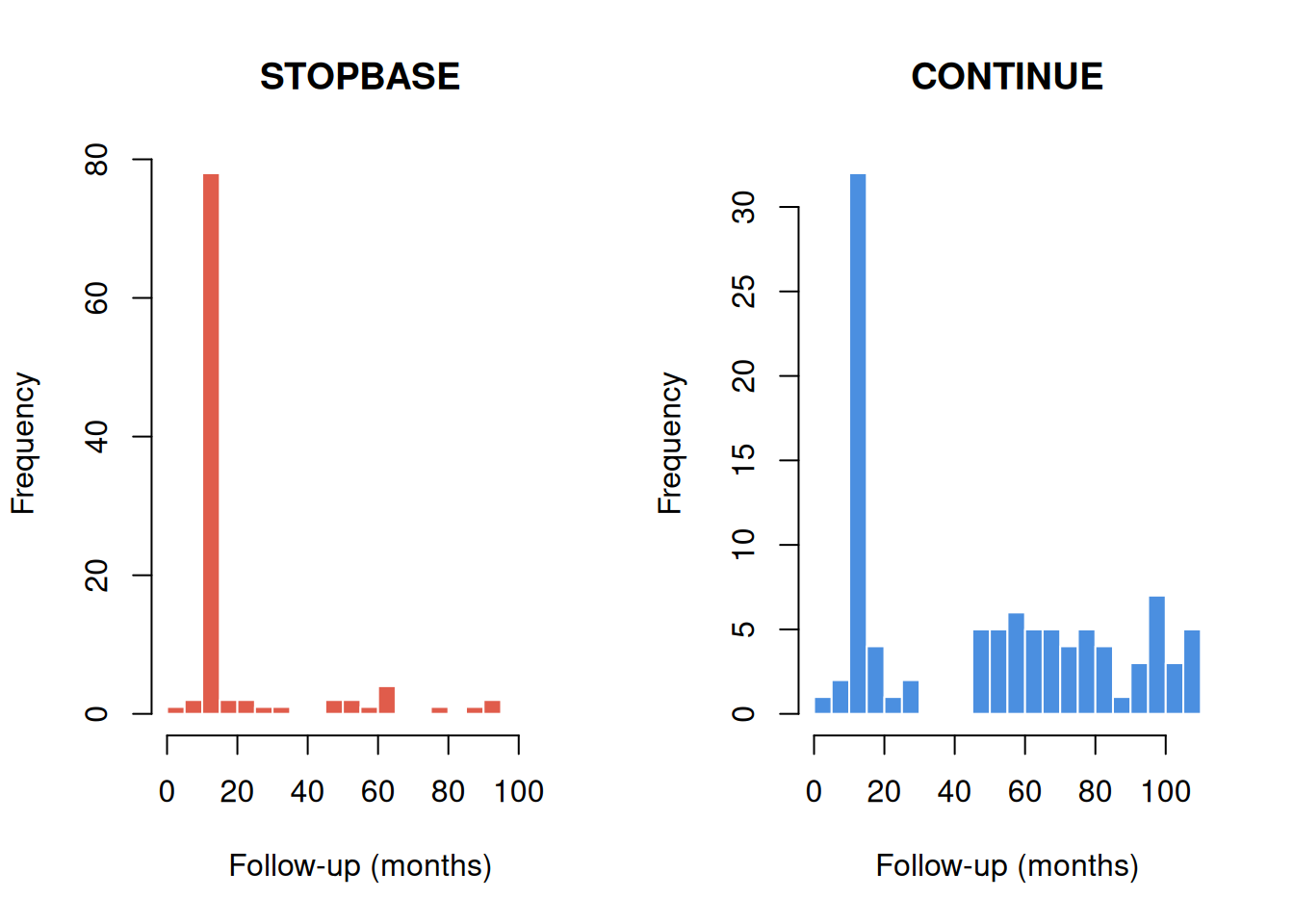
Figure 2: Follow-up time by arm and censoring type.
As expected, most STOPBASE clones are censored (those who continued getting annual mammograms), while only a minority of CONTINUE clones are censored (those who stopped getting mammograms).
5 Step 3: Descriptive Analysis
Before fitting weighted outcome models, it is useful to describe the data and examine crude survival by arm.
Code
# Compute monthly event rate per arm
arms <- c("STOPBASE", "CONTINUE")
cols <- c("#E05C4B", "#4B8FE0")
plot(NA,
xlim = c(0, 70), ylim = c(0, 0.15),
xlab = "Months since study entry",
ylab = "Cumulative mortality (crude)",
main = "Crude cumulative mortality by arm"
)
for (j in seq_along(arms)) {
sub <- long_data[long_data$arm == arms[j], ]
# Month-by-month event counts
max_t <- max(sub$month2)
cum_mort <- numeric(max_t + 1L)
n_risk <- numeric(max_t + 1L)
for (t in 0:max_t) {
rows_t <- sub[sub$month2 == t, ]
n_risk[t + 1L] <- nrow(rows_t)
cum_mort[t + 1L] <- sum(rows_t$dead_t1 == 1L, na.rm = TRUE)
}
cum_mort <- cumsum(cum_mort) / max(n_risk, 1L)
lines(0:max_t, cum_mort, col = cols[j], lwd = 2)
}
legend("topleft",
legend = arms, col = cols, lwd = 2, bty = "n"
)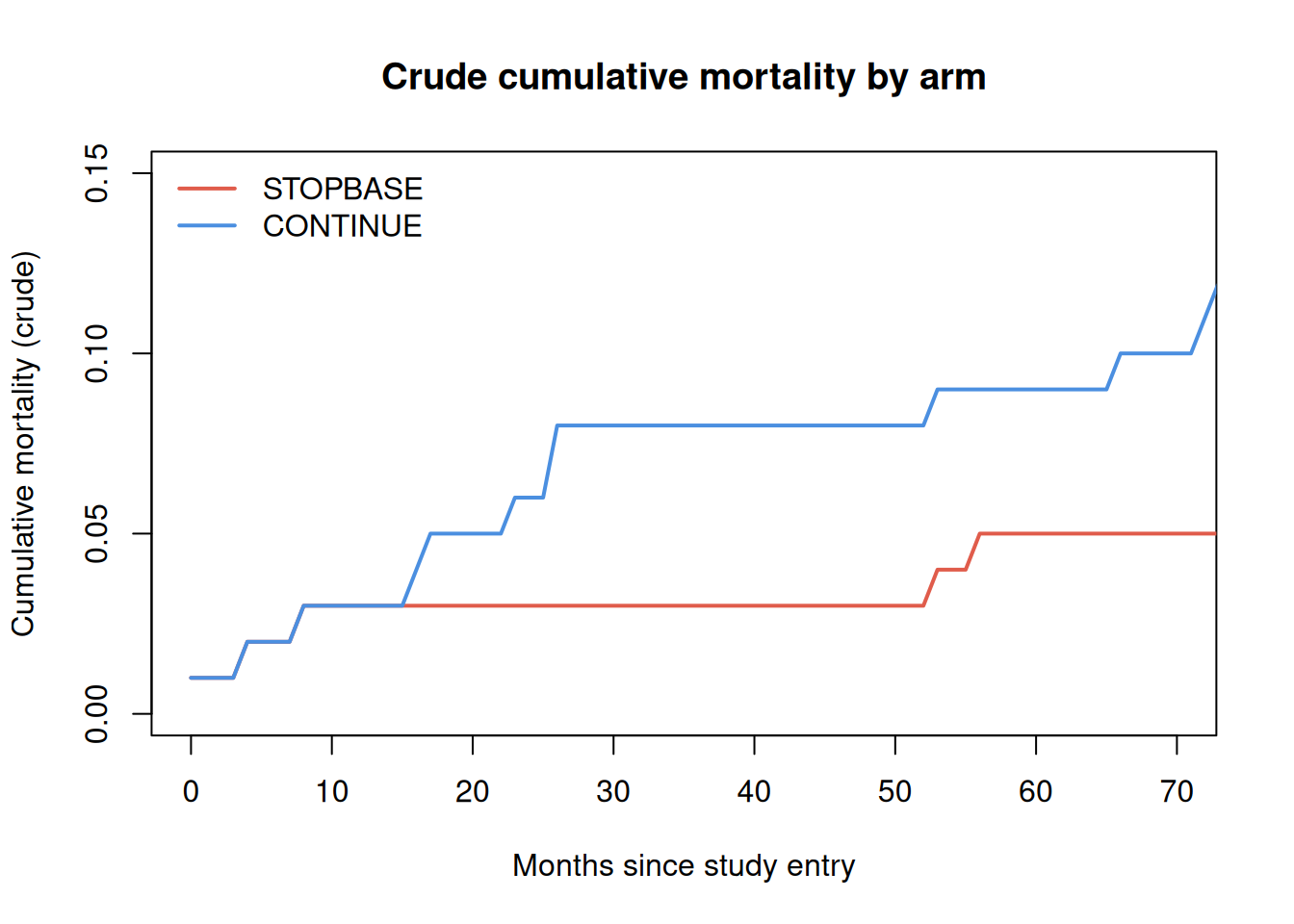
Figure 3: Empirical cumulative mortality by arm (crude, without IPW). Under the null, the two arms should be similar because clones are derived from the same participants.
Note
The crude curves above do not account for the informative censoring introduced by the clone-censor step. In a complete analysis, inverse probability weights (IPW) would be applied to correct for the different censoring mechanisms in each arm. See García-Albéniz et al. (2020) for the full weighted analysis.