Chapter 6: Graphical Representation of Causal Effects
So far we have used potential outcomes to represent causal effects. In this chapter we use causal diagrams—directed acyclic graphs (DAGs)—to represent causal relations. Causal diagrams encode our qualitative assumptions about the causal structure of the problem and allow us to determine when association equals causation, and which variables need to be adjusted for to eliminate confounding.
1 6.1 Causal Diagrams (pp. 59–61)
A causal diagram is a directed acyclic graph (DAG) in which:
- Each node (vertex) represents a variable
- Each directed edge (arrow) from node \(V\) to node \(W\) represents a direct causal effect of \(V\) on \(W\)
- There are no cycles: following the arrows, you can never return to a starting node
Definition 1 (Directed Acyclic Graph (DAG)) A directed acyclic graph (DAG) used as a causal diagram represents a non-parametric structural equation model (NPSEM). For each variable \(V_k\) with parents \(\mathrm{pa}(V_k)\) in the graph, there is a structural equation:
\[V_k = f_k\bigl(\mathrm{pa}(V_k),\, U_k\bigr)\]
where \(U_k\) is an unmeasured background variable (exogenous variable) that represents all causes of \(V_k\) not otherwise shown in the graph.
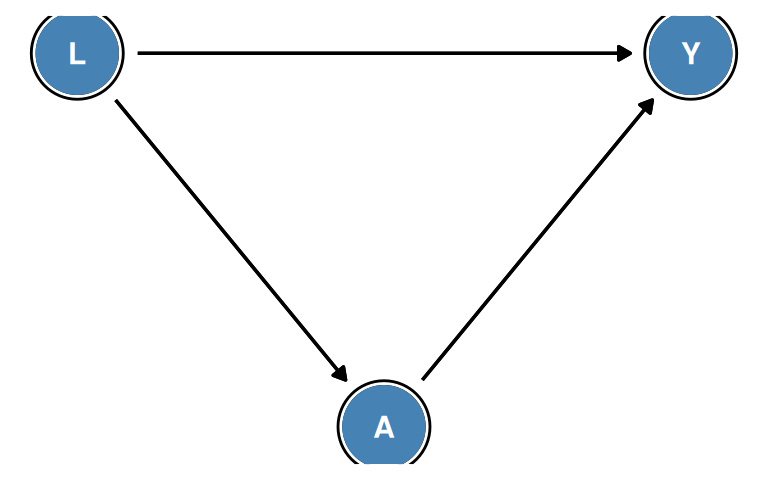
The Main Example
Consider a study of the causal effect of treatment \(A\) on outcome \(Y\), where \(L\) is a measured variable that causes both \(A\) and \(Y\). The structural equations are:
\[L = f_L(U_L)\] \[A = f_A(L,\, U_A)\] \[Y = f_Y(L,\, A,\, U_Y)\]
where \(U_L\), \(U_A\), and \(U_Y\) are mutually independent unmeasured background variables. The corresponding causal diagram is:
DAG Terminology
For a node \(W\) in a causal diagram:
- A parent of \(W\) is any node with a direct arrow into \(W\)
- A child of \(W\) is any node that \(W\) has a direct arrow into
- An ancestor of \(W\) is any node from which \(W\) is reachable by following arrows
- A descendant of \(W\) is any node reachable from \(W\) by following arrows
- A path between two nodes is any sequence of nodes connected by edges (arrows), regardless of direction
In Figure 6.1: \(L\) is a parent of \(A\) and a parent of \(Y\); \(A\) is a child of \(L\); \(Y\) is a descendant of \(L\) via two paths (\(L \to Y\) directly, and \(L \to A \to Y\)).
What DAG Arrows Represent
The presence of an arrow \(V \to W\) encodes the assumption that \(V\) has a direct causal effect on \(W\) (i.e., not entirely mediated by other variables explicitly shown in the graph).
The absence of an arrow between \(V\) and \(W\) (with no directed path from \(V\) to \(W\)) encodes the assumption that \(V\) has no direct causal effect on \(W\), given the other variables in the graph. This is a substantive causal assumption that must be justified by subject-matter knowledge.
2 6.2 Causal Diagrams and Marginal Independence (pp. 61–64)
Causal diagrams encode information about which variables are marginally independent (independent unconditionally, before conditioning on any variable). We can read this information directly from the graph structure.
Open and Blocked Paths
A path between two nodes \(V\) and \(W\) is either open or blocked:
- A path is blocked if it contains a collider node — a node where two arrowheads meet on the path: \(\cdots \to C \leftarrow \cdots\)
- A path is open if it contains no collider (all intermediate nodes are non-colliders)
Two variables are marginally associated if and only if there is at least one open path between them.
Example 1 (Marginal Independence: Key Examples) Example 1: \(A \rightarrow Y\)
- One open path \(A \to Y\): \(A\) and \(Y\) are associated
Example 2: \(A \quad Y\) (no path)
- No path between \(A\) and \(Y\): they are independent
Example 3: \(A \leftarrow L \rightarrow Y\) (fork with common cause \(L\))
- One open path \(A \leftarrow L \to Y\) (non-collider \(L\) not conditioned on)
- \(A\) and \(Y\) are associated even though \(A\) does not cause \(Y\)
Example 4: \(A \rightarrow C \leftarrow Y\) (collider at \(C\))
- The only path \(A \to C \leftarrow Y\) is blocked by the collider \(C\)
- \(A\) and \(Y\) are independent marginally
3 6.3 Causal Diagrams and Conditional Independence (pp. 64–68)
Conditioning on a variable — by stratifying, restricting, or including it in a regression — can change independence relationships. Whether conditioning on a variable opens or blocks a path depends on whether that variable is a collider or a non-collider on the path.
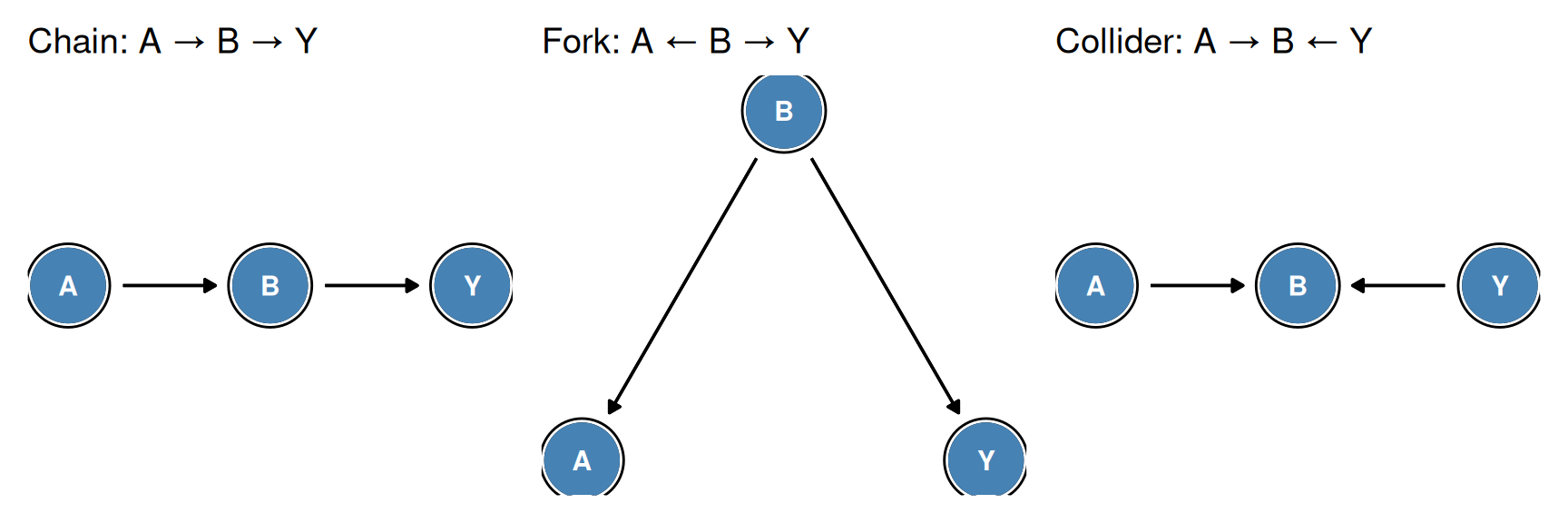
Three Fundamental Path Structures
1. Chain: \(A \rightarrow B \rightarrow Y\)
- Marginally: \(A\) and \(Y\) are associated (open path \(A \to B \to Y\))
- Conditional on \(B\): \(A\) and \(Y\) are independent — conditioning on the intermediate variable \(B\) blocks the path
2. Fork: \(A \leftarrow B \rightarrow Y\)
- Marginally: \(A\) and \(Y\) are associated (open path through common cause \(B\))
- Conditional on \(B\): \(A\) and \(Y\) are independent — conditioning on the common cause \(B\) blocks the non-causal association
3. Collider: \(A \rightarrow B \leftarrow Y\)
- Marginally: \(A\) and \(Y\) are independent (path blocked by collider \(B\))
- Conditional on \(B\): \(A\) and \(Y\) are dependent — conditioning on a collider opens the previously blocked path
Collider Stratification Bias
Collider stratification bias is a subtle and important source of spurious association that arises from conditioning on a common effect of two variables.
Example 2 (Collider Stratification Bias: Aspirin, Smoking, and Hospitalization) Consider two variables that are independent in the general population:
- \(A\): regular aspirin use
- \(B\): smoking
Both \(A\) and \(B\) independently cause hospitalization (\(C\)):
\[A \longrightarrow C \longleftarrow B\]
In the general population: aspirin use \(A\) and smoking \(B\) are independent — knowing someone uses aspirin tells you nothing about whether they smoke.
Among hospitalized patients (\(C = 1\)): aspirin use and smoking become negatively associated. If a hospitalized patient does not use aspirin, it is more likely their hospitalization is due to smoking-related disease. If a hospitalized patient does not smoke, their admission is more likely due to a cardiovascular condition related to aspirin use.
This spurious negative association between \(A\) and \(B\) among the hospitalized is collider stratification bias: conditioning on hospitalization \(C\) opens the previously blocked path \(A \to C \leftarrow B\).
D-separation Rules (Summary)
The complete rules for determining whether a path is open or blocked after conditioning on a set \(Z\):
| Node type on path | \(B \notin Z\) (not conditioned on) | \(B \in Z\) (conditioned on) |
|---|---|---|
| Non-collider (chain or fork) | Open | Blocked |
| Collider | Blocked | Open |
Two variables are d-separated given \(Z\) if every path between them is blocked given \(Z\). D-separated variables are (conditionally) independent in any distribution generated by the NPSEM.
4 6.4 Positivity and Structural Causal Models (pp. 68–69)
Non-Parametric Structural Equation Models
Causal diagrams and their associated structural equations constitute non-parametric structural equation models (NPSEMs). The NPSEM framework provides a rigorous basis for defining counterfactual quantities from the observed data structure.
Given the structural equations \(L = f_L(U_L)\), \(A = f_A(L, U_A)\), \(Y = f_Y(L, A, U_Y)\) with \(U_L\), \(U_A\), \(U_Y\) mutually independent, the counterfactual outcome \(Y^a\) is formally defined as:
\[Y^a = f_Y\bigl(L,\, a,\, U_Y\bigr)\]
That is, \(Y^a\) is the value \(Y\) would take if we intervened to set \(A = a\), leaving all other structural equations (including those for \(L\) and the \(U\) variables) unchanged. This corresponds to Pearl’s do-operator: \(Y^a \equiv Y \,\mathrm{do}(A=a)\).
Positivity in Structural Causal Models
The positivity assumption requires that every individual has a positive probability of receiving each treatment level:
\[\Pr[A = a \mid L = l] > 0 \quad \text{for all } a \text{ and all } l \text{ with } \Pr[L = l] > 0\]
In structural equation terms, positivity requires that the function \(f_A(L, U_A)\) is not deterministic — no value of \(L\) should completely determine the treatment assignment \(A\).
Structural positivity violations occur when \(L\) deterministically forces \(A\) to a particular value. In these strata, the counterfactual \(Y^a\) cannot be identified from observational data regardless of sample size.
Random positivity violations occur when, by chance, certain \((A, L)\) combinations do not appear in the finite sample, even though they have positive probability in the population.
5 6.5 A Structural Classification of Bias (pp. 69–73)
Causal diagrams provide a structural classification of the biases that may affect causal estimates. Three main types arise from the structure of the causal diagram.
Confounding Bias
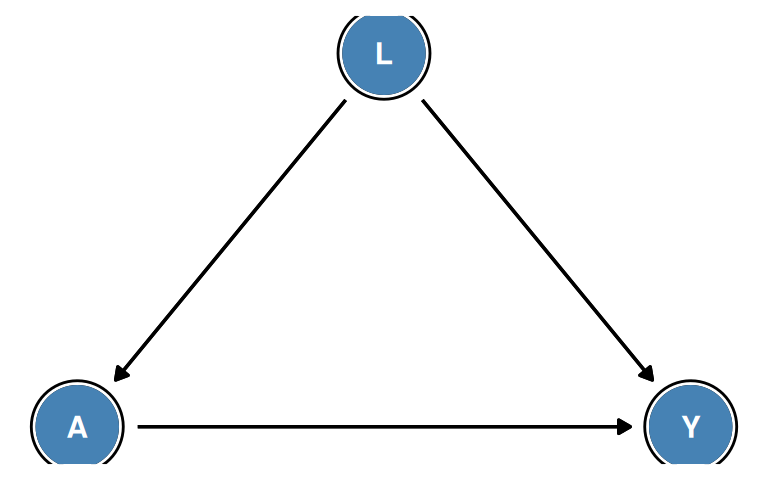
Confounding is present when there is an open backdoor path from treatment \(A\) to outcome \(Y\).
Definition 2 (Backdoor Path) A backdoor path from \(A\) to \(Y\) is any path that:
- Starts with an arrow pointing into \(A\) (i.e., begins \(\cdots \to A\))
- Ends at \(Y\)
Such paths represent non-causal flows of association between \(A\) and \(Y\) induced by common causes.
Definition 3 (Confounding (Structural Definition)) Confounding of the effect of \(A\) on \(Y\) exists when there is at least one open backdoor path from \(A\) to \(Y\).
In the diagram \(L \to A\), \(L \to Y\), \(A \to Y\): the path \(A \leftarrow L \to Y\) is a backdoor path. Since \(L\) is a non-collider on this path and has not been conditioned on, the path is open. There is therefore confounding.
The Backdoor Criterion
Definition 4 (Backdoor Criterion) A set of measured variables \(L\) satisfies the backdoor criterion for estimating the causal effect of \(A\) on \(Y\) if:
- No variable in \(L\) is a descendant of \(A\)
- \(L\) blocks every backdoor path from \(A\) to \(Y\)
When \(L\) satisfies the backdoor criterion, adjusting for \(L\) (via stratification, standardization, or IP weighting) eliminates confounding and yields an unbiased estimate of the causal effect.
Example 3 (Backdoor Criterion Example) DAG: \(U \to L \to A \to Y\), \(L \to Y\)
Backdoor path from \(A\) to \(Y\): \(A \leftarrow L \to Y\)
Does \(\{L\}\) satisfy the backdoor criterion?
- \(L\) is not a descendant of \(A\) ✓
- Conditioning on \(L\) (a non-collider on \(A \leftarrow L \to Y\)) blocks this path ✓
Yes — adjusting for \(L\) suffices to identify the causal effect, even though \(L\) has an unmeasured cause \(U\).
Does \(\{U\}\) satisfy the backdoor criterion?
No — \(U\) is an ancestor of \(L\) but is not on the backdoor path \(A \leftarrow L \to Y\). Conditioning on \(U\) alone does not block the path through \(L\).
Selection Bias
Selection bias arises when the analysis conditions on a variable \(C\) that is a collider (or ancestor/descendant of a collider) on a path between \(A\) and \(Y\).
Structural representation:
\[A \longrightarrow C \longleftarrow Y\]
Restricting the analysis to individuals with \(C = 1\) (e.g., individuals selected into the study) opens the path \(A \to C \leftarrow Y\) and induces a spurious association between \(A\) and \(Y\).
Measurement Bias
Measurement bias (information bias) occurs when a variable is measured imperfectly. In the causal diagram, we distinguish:
- \(A\): the true (unmeasured or imperfectly measured) treatment
- \(A^*\): the observed (potentially error-prone) measurement of treatment
The structural relationship is \(A \to A^*\): the true value generates the measurement, with additional unmeasured factors \(U_{A^*}\) affecting the measurement.
Structural representation:
\[A \longrightarrow Y \qquad A \longrightarrow A^*\]
Using \(A^*\) in place of \(A\) produces a biased estimate of the causal effect of \(A\) on \(Y\).
6 6.6 The Structure of Effect Modification (pp. 73–76)
Effect Modification in Causal Diagrams
Effect modification (heterogeneity of treatment effects) occurs when the causal effect of \(A\) on \(Y\) differs across levels of another variable \(V\). Standard DAGs, however, cannot directly represent effect modification.
A DAG with \(V \to Y\) and \(A \to Y\) is compatible with:
- No effect modification: the \(A \to Y\) effect is the same for all values of \(V\)
- Effect modification: the \(A \to Y\) effect varies across levels of \(V\)
Both cases have identical qualitative structure. The DAG encodes only the presence of causal effects (which variables cause which), not their magnitude or heterogeneity.
Confounders, Effect Modifiers, and Both
A variable \(V\) can play different roles with respect to the \(A \to Y\) effect:
- Confounder: opens a backdoor path (\(V \to A\), \(V \to Y\)) — must adjust for \(V\) to remove bias
- Effect modifier: the \(A \to Y\) effect varies by \(V\) — should stratify by \(V\) to fully characterize effects
- Both: must adjust for \(V\) (confounding) and stratify (modification)
- Neither: \(V\) is unrelated to the \(A \to Y\) causal structure
Example 4 (Confounder and Effect Modifier Roles) Scenario 1: \(V\) is a confounder only
\[V \to A \to Y, \quad V \to Y\]
\(V\) opens the backdoor path \(A \leftarrow V \to Y\). We must adjust for \(V\) to remove confounding. Whether the \(A \to Y\) effect varies by \(V\) is a separate empirical question.
Scenario 2: \(V\) is an effect modifier only (in a randomized trial)
\[V \to Y, \quad A \to Y, \quad \text{($A$ randomized, no } V \to A \text{ arrow)}\]
No backdoor paths exist (randomization removes \(V \to A\)). Adjustment for \(V\) is not needed to remove bias. However, if the \(A \to Y\) effect varies by \(V\), we should report stratum-specific estimates.
Scenario 3: \(V\) is both confounder and effect modifier
\[V \to A \to Y, \quad V \to Y, \quad \text{($A$-$Y$ effect varies by $V$)}\]
We must adjust for \(V\) (removes confounding) and report stratum-specific effects (captures modification).
Identifying Effect Modification
Because DAGs cannot directly represent effect modification, we must assess it empirically:
- First, ensure the causal effect is identified within each stratum of \(V\) (using the backdoor criterion or other identification strategies)
- Estimate stratum-specific causal effects \(\text{E}{\left[Y^{a=1} - Y^{a=0} \mid V = v\right]}\) for each level \(v\)
- Compare effect estimates across strata: if they differ, effect modification is present
7 Summary
This chapter introduced causal diagrams (DAGs) as graphical tools for encoding causal assumptions and determining the identifiability of causal effects from observed data.
Key concepts:
DAGs and NPSEMs: A DAG represents a non-parametric structural equation model. Each variable \(V_k\) satisfies \(V_k = f_k(\mathrm{pa}(V_k), U_k)\) with mutually independent background variables \(U_k\)
Marginal independence: Two variables are marginally independent if all paths between them are blocked (d-separated). A collider on a path blocks it marginally.
-
Three fundamental path structures:
- Chain (\(A \to B \to Y\)): Conditioning on \(B\) blocks the path
- Fork (\(A \leftarrow B \to Y\)): Conditioning on \(B\) blocks the path
- Collider (\(A \to B \leftarrow Y\)): Conditioning on \(B\) opens the path — collider stratification bias
Positivity and NPSEMs: The positivity assumption requires that treatment assignment is not deterministic given \(L\). Counterfactuals \(Y^a\) are formally defined via the structural equations as \(Y^a = f_Y(L, a, U_Y)\)
-
Structural classification of bias:
- Confounding: open backdoor path from \(A\) to \(Y\) (common cause not conditioned on)
- Selection bias: conditioning on a collider (common effect) on a path between \(A\) and \(Y\)
- Measurement bias: using an imperfect measure \(A^*\) instead of the true \(A\)
Backdoor criterion: A set \(L\) satisfying (i) no descendant of \(A\) in \(L\), (ii) \(L\) blocks all backdoor paths — adjusting for \(L\) eliminates confounding
Effect modification: Standard DAGs encode qualitative structure only; effect modification cannot be read from the DAG and must be assessed empirically
8 References
Hernán, Miguel A, and James M Robins. 2020. Causal Inference: What If. Chapman & Hall/CRC. https://miguelhernan.org/whatifbook.